Many years ago, when I was still in possession of my hair, I entered a subcontract to develop a system to replace paper-based case files for a quango in South Africa.
The main contract was held by a large development shop that specialised in a related, but different field. They had given one of their systems analysts the task of analysing the system (duh!) but had no spare capacity to code it, so they farmed it out to me.
Lots of people tell you how to do things properly. Here are some things I’ve inherited in our Ansible that break things in horrible ways.

Coupling is (roughly) how interconnected different components of a system are. One of the most common patterns in modern software engineering is loose coupling.
The idea of separating things across an API so that you can change things behind the API without having to change other components is very powerful.

I am a great fan of the DBRE book, and an avid follower of the authors’ podcasts, videos and blog posts.
But there is one glaring omission that I can’t find discussed properly anywhere: upgrades.
You need to patch to fix bugs or address vulnerabilities. You need to upgrade for support and new features that developers want.
I understand that site-specific needs make it hard to proclaim detailed edicts. But the DBRE book isn’t about detailed edicts. It’s about principles and a way of working.
The lean model for continuous improvement looks something like this:
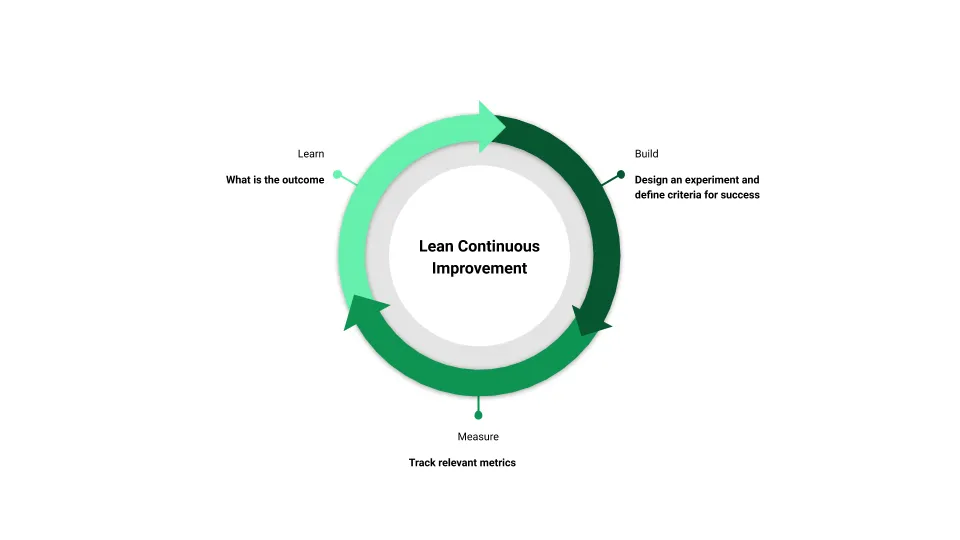
Where you start is a matter of some debate, as is the direction of flow. However, most people start with the idea of building a Minimum Viable Product (MVP) as an experiment; measuring the results; and then learning from the measures they recorded, which then feeds into the next build of the product.
What is an MVP for a Database Reliability Engineer (DBRE)? A good, old-fashioned manual install. A best practices manual install.
Part 1 looks at some principles and introduces some of the tools in your arsenal.
Part 2 covers the dreaded PostgreSQL bloat issue as well as how TOAST can help performance, or hinder it.
Part 3 dives deeper into identifying, investigating and mitigating slow queries.
Part 4 covers indexes.
Part 5 (this post) covers rewriting queries.
bench=# \d pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
aid | integer | | not null |
bid | integer | | |
abalance | integer | | |
filler | character(84) | | |
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
"i_pa2" btree (aid, abalance, bid) WHERE aid > 0 AND aid < 194999 AND abalance < '-4500'::integer AND abalance > '-5000'::integer
Foreign-key constraints:
"pgbench_accounts_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid)
Referenced by:
TABLE "pgbench_history" CONSTRAINT "pgbench_history_aid_fkey" FOREIGN KEY (aid) REFERENCES pgbench_accounts(aid)
bench=# \d pgbench_branches
Table "public.pgbench_branches"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
bid | integer | | not null |
bbalance | integer | | |
filler | character(88) | | |
Indexes:
"pgbench_branches_pkey" PRIMARY KEY, btree (bid)
Referenced by:
TABLE "pgbench_accounts" CONSTRAINT "pgbench_accounts_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid)
TABLE "pgbench_history" CONSTRAINT "pgbench_history_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid)
TABLE "pgbench_tellers" CONSTRAINT "pgbench_tellers_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid)
bench=# \d pgbench_history
Table "public.pgbench_history"
Column | Type | Collation | Nullable | Default
--------+-----------------------------+-----------+----------+---------
tid | integer | | |
bid | integer | | |
aid | integer | | |
delta | integer | | |
mtime | timestamp without time zone | | |
filler | character(22) | | |
Indexes:
"i1" btree (aid, delta) WHERE delta < 0
Foreign-key constraints:
"pgbench_history_aid_fkey" FOREIGN KEY (aid) REFERENCES pgbench_accounts(aid)
"pgbench_history_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid)
"pgbench_history_tid_fkey" FOREIGN KEY (tid) REFERENCES pgbench_tellers(tid)
bench=# \d pgbench_tellers
Table "public.pgbench_tellers"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
tid | integer | | not null |
bid | integer | | |
tbalance | integer | | |
filler | character(84) | | |
Indexes:
"pgbench_tellers_pkey" PRIMARY KEY, btree (tid)
Foreign-key constraints:
"pgbench_tellers_bid_fkey" FOREIGN KEY (bid) REFERENCES pgbench_branches(bid)
Referenced by:
TABLE "pgbench_history" CONSTRAINT "pgbench_history_tid_fkey" FOREIGN KEY (tid) REFERENCES pgbench_tellers(tid)
We have already covered one aspect of query rewriting, namely how to rewrite joins, which we covered in Query Performance Improvement Part 3.
Part 1 looks at some principles and introduces some of the tools in your arsenal.
Part 2 covers the dreaded PostgreSQL bloat issue as well as how TOAST can help performance, or hinder it.
Part 3 dives deeper into identifying, investigating and mitigating slow queries.
Part 4 (this post) covers indexing.
Part 5 covers rewriting queries.
Indexes are one of the most effective tools to improve query performance. Indexes work best when they return a small subset of data and are small compared to row size. So an 8-byte integer index on a 2kB row is more efficient than a 1kB text index on a 1.5kB row.
Part 1 looks at some principles and introduces some of the tools in your arsenal.
Part 2 covers the dreaded PostgreSQL bloat issue as well as how TOAST can help performance, or hinder it.
Part 3 (this post) dives deeper into identifying, investigating and mitigating slow queries.
Part 4 covers indexing.
Part 5 covers rewriting queries.
EXPLAIN to examine an explain planEXPLAIN (ANALYZE) can be dangerous!The most reliable way of identifying slow queries is to enable slow query logging using the parameter log_min_duration_statement. The pain threshold varies by environment, but for example if you wanted to log all queries that take longer than 50ms, you would issue the following command in psql:
Part 1 looks at some principles and introduces some of the tools in your arsenal.
Part 2 (this post) covers the dreaded PostgreSQL bloat issue as well as how TOAST can help performance, or hinder it.
Part 3 dives deeper into identifying, investigating and mitigating slow queries.
Part 4 covers indexing.
Part 5 covers rewriting queries.
Strictly speaking, bloat is the unused space left behind by a VACUUM that is not a VACUUM FULL.
Part 1 (this post) looks at some principles and introduces some of the tools in your arsenal.
Part 2 covers the dreaded PostgreSQL bloat issue as well as how TOAST can help performance, or not.
Part 3 dives deeper into identifying, investigating and mitigating slow queries.
Part 4 covers indexing.
Part 5 covers rewriting queries.
Welcome to this series of blog posts which will hopefully walk you through everything you need to know about improving query performance, specifically in PostgreSQL. The basic principles apply to all databases, though, even if implementation differences mean that different databases find different things painful.